M42 unveils a pioneering framework for evaluating clinical LLMs
M42, a global healthcare group based in Abu Dhabi and part of the G42 group, has unveiled a pioneering framework to evaluate large language models (LLMs) for clinical applications.
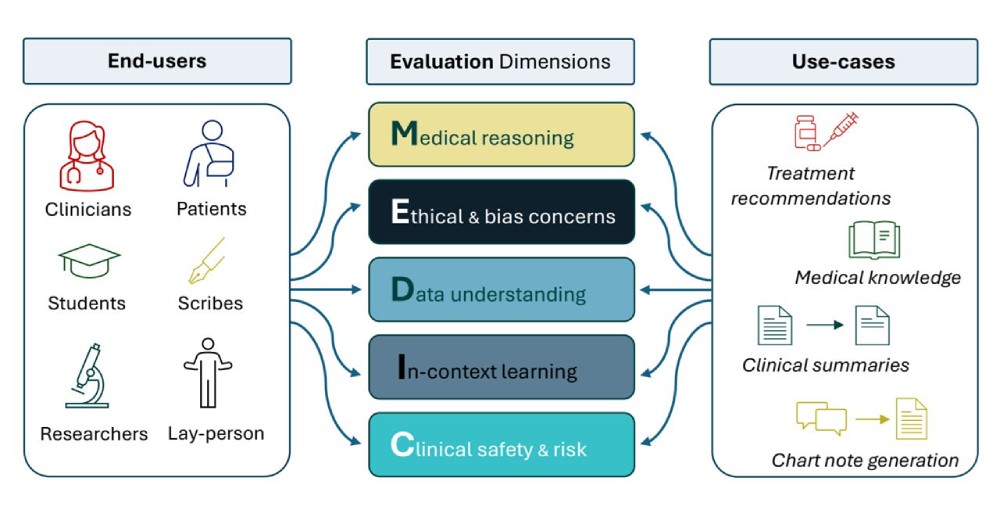
The new framework, named MEDIC, aims to address the challenges in deploying generative AI in healthcare by assessing five crucial areas: Medical reasoning, Ethics and bias, Data understanding, In-context learning, and Clinical safety. By providing a holistic view of LLM performance, MEDIC helps ensure that these models can be used safely and effectively in healthcare environments.
How does it work?
The MEDIC framework evaluates LLMs by examining five key dimensions essential for healthcare applications: medical reasoning, ethical and bias considerations, data and language understanding, in-context learning, and clinical safety. It employs a cross-examination approach to assess how well models perform on tasks such as medical question-answering, summarization, and generating clinical notes. Importantly, MEDIC does not rely on traditional reference outputs for evaluation but instead quantifies model performance based on factors like coverage and hallucination detection.
By highlighting discrepancies in performance between general-purpose models and those specifically fine-tuned for medical applications, MEDIC provides valuable insights into where specific models excel or fall short. This comprehensive evaluation framework, developed by M42's AI research team in partnership with other AI and medical experts, is the first of its kind to holistically assess the safety, ethical implications, and practical utility of LLMs in healthcare.
M42 is also working on making the framework accessible to other researchers by open-sourcing the necessary code for conducting these evaluations.
Why does it matter?
Generative AI has the potential to revolutionize healthcare by alleviating the burden on healthcare professionals, providing specialized knowledge on demand, and enhancing patient care and preventative health measures. However, the healthcare sector requires absolute precision and reliability due to the critical nature of medical information and advice. This creates a gap between the promise of generative AI and its actual implementation in clinical settings.
The MEDIC framework addresses this gap by offering a robust method for evaluating the clinical safety, ethical considerations, and overall performance of LLMs. By setting a standard for evaluation, MEDIC supports healthcare professionals, AI developers, and policymakers in making informed decisions about which models are suitable for clinical use.
As the framework identifies both strengths and areas for improvement, it enables the development of more reliable and effective AI tools for healthcare.
The context
The MEDIC framework builds on M42's ongoing efforts to advance AI in healthcare. Last year, M42 released Med42, its first clinical LLM, which was made available for review and testing by academic and healthcare institutions worldwide. Following feedback from the global healthcare community, M42 launched Med42 V2, a significant upgrade built on Meta's LLaMA-3, available in versions with 8 billion and 70 billion parameters. The MEDIC framework represents the next step in this evolution, providing a structured approach to evaluating LLMs to ensure their safe and effective use in clinical contexts.
By addressing the unique challenges posed by the use of AI in healthcare, the MEDIC framework sets a new benchmark for evaluating clinical language models. Its open-source approach invites broader collaboration, potentially accelerating the development of AI tools that are both effective and safe for healthcare professionals and patients alike.
Latest @ 
Dubai creates $100M fund to become global health tech hub
Qatar Red Crescent launches HAKEEM digital health platform
💡Did you know?
You can take your DHArab experience to the next level with our Premium Membership.👉 Click here to learn more
🛠️Featured tool
 Easy-Peasy
Easy-Peasy
An all-in-one AI tool offering the ability to build no-code AI Bots, create articles & social media posts, convert text into natural speech in 40+ languages, create and edit images, generate videos, and more.
👉 Click here to learn more
