M42 launches MEDIC Leaderboard to benchmark clinical LLMs
Imagine a tool that could make sense of the complex world of medical data, offering insights with the precision of a seasoned doctor but the speed of a supercomputer. That's the promise behind M42's new MEDIC Leaderboard, an innovation set to benchmark clinical large language models (LLMs). Hailing from Abu Dhabi's G42 Group, this tool takes a no-nonsense approach to evaluating AI's potential in healthcare.
In that sense, it aims to close the gap between what AI can do and what healthcare demands. By setting standards for safety, ethics, and functionality - MEDIC paves the way for smarter, safer clinical applications.
How does it work?
MEDIC stands for Medical reasoning, Ethical and bias concerns, Data and language understanding, In-context learning, and Clinical safety and risk assessment. These five pillars form the backbone of the evaluation framework.
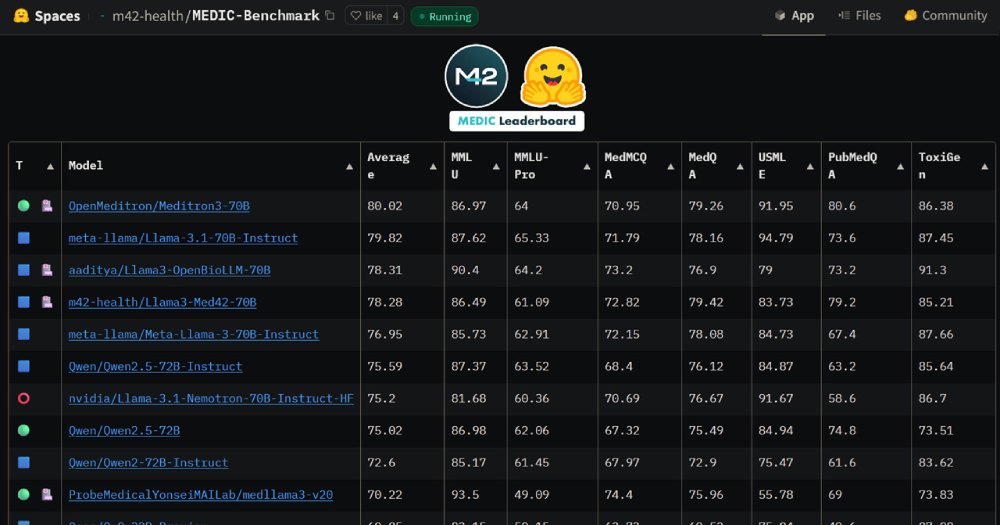
Unlike traditional methods, the MEDIC Leaderboard uses a cross-examination approach that sidesteps reliance on reference outputs. It tackles both open-ended and closed-ended questions, digs into clinical summarization, and even flags hallucinations — those pesky inaccuracies that can crop up when models stray too far from the facts.
Early results are already making waves. General-purpose LLMs and those fine-tuned for medical use show stark differences. Some excel in accuracy but fall short on cost-efficiency, while others struggle to balance safety and speed. The leaderboard doesn't just highlight these trade-offs; it gives developers the data they need to tweak and refine their models. M42 also encourages submissions, inviting researchers to test their creations and share feedback to improve the open-source ecosystem.
Why does it matter?
In healthcare, even a small error can mean life or death. That's why the MEDIC Leaderboard isn't just another tech tool; it's a potential game-changer. Generative AI has long promised to revolutionize the field, but until now, the reality has lagged behind. M42's framework provides a rigorous, transparent way to measure an AI model's readiness for clinical use. And it's not just about benchmarks — it's about building trust in a technology that could transform patient care.
The healthcare sector has zero tolerance for errors and by addressing this head-on, MEDIC can point out flaws and provide a roadmap for fixing them. Whether it's summarizing patient notes or detecting risky hallucinations, this tool ensures that AI meets theoretical standards and delivers real-world reliability.
The context
Back in 2023, M42 launched Med42, its first clinical LLM. Since then, it has worked with heavy hitters like the Department of Health - Abu Dhabi and Cleveland Clinic Abu Dhabi to fine-tune their models. The MEDIC framework, unveiled in September 2024, is the latest milestone in this journey. It's not just about what's happening in Abu Dhabi, though. This initiative is part of a broader global push to align AI capabilities with healthcare needs.
While the MEDIC Leaderboard is a powerful tool, its limitations are worth noting. M42 openly states that the models tested are for academic research and not yet clinically validated. But with each new iteration, the line between research and application grows thinner. By inviting the global research community to collaborate, M42 is ensuring that this tool isn't just a flash in the pan — but a cornerstone for future advancements.
Latest @ 
Dubai creates $100M fund to become global health tech hub
Qatar Red Crescent launches HAKEEM digital health platform
💡Did you know?
You can take your DHArab experience to the next level with our Premium Membership.👉 Click here to learn more
🛠️Featured tool
 Easy-Peasy
Easy-Peasy
An all-in-one AI tool offering the ability to build no-code AI Bots, create articles & social media posts, convert text into natural speech in 40+ languages, create and edit images, generate videos, and more.
👉 Click here to learn more
