Google unveils MedGemma 1.5 and medical speech-to-text with MedASR
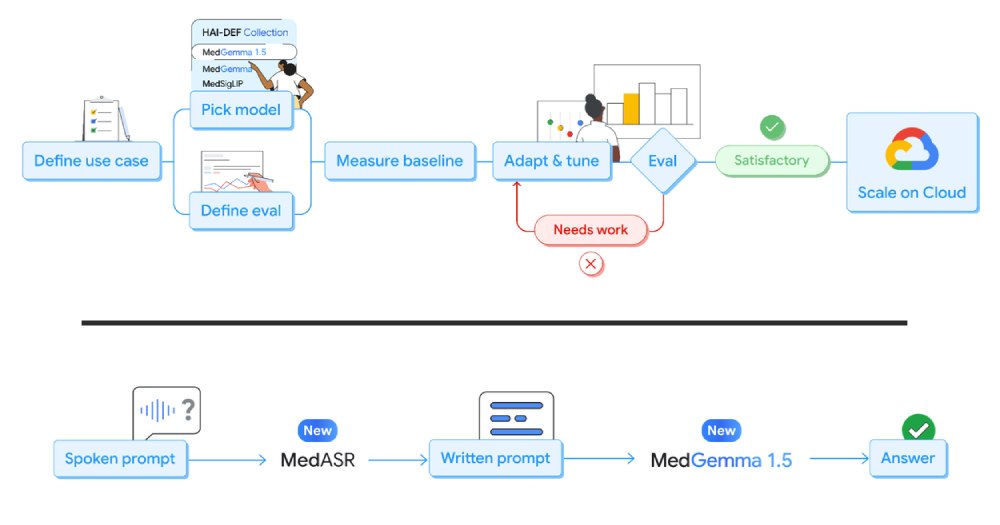
There's a quiet revolution underway in healthcare tech. Google just dropped a double whammy of open AI tools built for medical research and development. One is MedGemma 1.5, an updated vision-language model that can handle complicated medical images and text. The other is MedASR, a speech-to-text system tuned for clinical talk. Together, they signal a big shift toward community-driven AI in healthcare.
Google calls these models starting points for innovation. They aren't finished clinical products. They are tools that researchers and developers can adapt, fine-tune, and build on for real-world healthcare tasks.
How does it work?
At the heart of this update are two clever pieces of tech.
MedGemma 1.5
- It ties together images and text in one model. Think of it as a smart bridge between radiology visuals and clinical notes.
- Unlike its predecessor, this version can take in high-dimensional data like CT scans and MRI volumes.
- It also tackles multiple image slices or patches at once, useful for histopathology and longitudinal imaging.
- This isn't some black box that spits out diagnoses. It answers questions, summarizes reports, and pulls out structured data from images and text for research workflows.
MedASR
- Built on a Conformer architecture and trained on medical speech, this model turns clinician dictation and conversations into text like a champ.
- It drastically cuts transcription errors compared with general speech systems, especially on tasks like radiology dictation.
- You can even use it to voice-command or prompt MedGemma itself, creating a more natural human-AI workflow.
Why does it matter?
There are a few reasons this matters, big time.
First, Google didn't lock this tech behind enterprise contracts. These are open models anyone can access, use, and tweak. That opens the door for startups, universities, nonprofits, and smaller players to innovate with fewer barriers.
Second, MedGemma 1.5 isn't just looking at flat images. It sees complexity — three-dimensional scans and longitudinal series of images. That's closer to what practicing clinicians actually use.
And the speech piece? Doctors, nurses, and clinicians talk more than they type. A dedicated medical speech model reduces errors dramatically compared to generic systems. That means fewer transcription errors and a smoother workflow for research tools that use that text.
Finally, this combo lets researchers prototype and iterate faster. Instead of buying expensive medical AI tools or building everything from scratch, you get a foundation you can tailor to your own data and protocols.
The context
The healthcare industry is adopting AI faster than almost any other sector. In fact, adoption is nearly twice the pace of the wider economy. That's hardly surprising. Clinicians wrestle with mountains of scans, reports, and dictated notes every day. AI that understands images, text, and speech can be a force multiplier in research settings before it ever hits patient care.
Google's Health AI Developer Foundations program already had MedGemma in its lineup. MedGemma 1.5 refines what came before with more imaging power and better text understanding. And Google is encouraging the community by hosting a MedGemma Impact Challenge with cash prizes for creative uses.
All of this sits against a backdrop where every AI player in tech is eyeing healthcare. But Google's open-source mindset gives researchers and developers something rare: the freedom to experiment without paying big licensing fees up front. It's a move that could democratize access to powerful tools in clinics, labs, and classrooms alike.
Latest @ 
What a pregnant woman eats can shape her child's health for life, new research shows
Dubai hospital becomes first in the Gulf to use advanced 3-in-1 heart artery imaging system
Abu Dhabi researchers find new clue in the fight against Huntington's disease
M42's national lab partners with Abbott to bring early cancer detection to the UAE
💡Did you know?
You can take your DHArab experience to the next level with our Premium Membership.👉 Click here to learn more
🛠️Featured tool
 Easy-Peasy
Easy-Peasy
An all-in-one AI tool offering the ability to build no-code AI Bots, create articles & social media posts, convert text into natural speech in 40+ languages, create and edit images, generate videos, and more.
👉 Click here to learn more
